Palantir and the Regulation of Life
Luke Munn
Luke Munn uses the body and code, objects and performances to activate relationships and responses. His projects have featured in the Kunsten Museum of Modern Art, the Centre de Cultura Contemporània de Barcelona, Fold Gallery London, Causey Contemporary Brooklyn and the Istanbul Contemporary Art Museum, with commissions from Aotearoa Digital Arts, and TERMINAL. He is a Studio Supervisor at Whitecliffe College of Art & Design and a current PhD Candidate at the Institute for Culture & Society, Western Sydney University.
Introduction
On January 30 Arthur Ureche, a forty year old union dues administrator, was driving his white Chevy compact through Los Angeles when he noticed 4 LAPD cruisers following him. Ureche’s last traffic violation was when he was nineteen, for driving too slow. But as he pulled over to let them pass, they stopped at a safe distance, exited their vehicles and trained their firearms on him. An officer barked out instructions using a megaphone, ordering Ureche to unlock his doors. The lock jammed. Ureche silently panicked, trying to comply without using any sudden movements. A helicopter whirred overhead. The officers waited. Ureche’s car had been identified as belonging to a wanted drug felon in California. But the car had Colorado plates. An automatic license plate reader had misidentified the vehicle. As journalist Chris Francescani (2014) noted, “same numbers; different states.” Though this tale may be dramatic, this text is ultimately interested in this less spectacular but more fundamental detail—exploring how the performances of software-infused systems produce new understandings, and how, in turn, these play out in the governance of ordinary people and everyday routines.
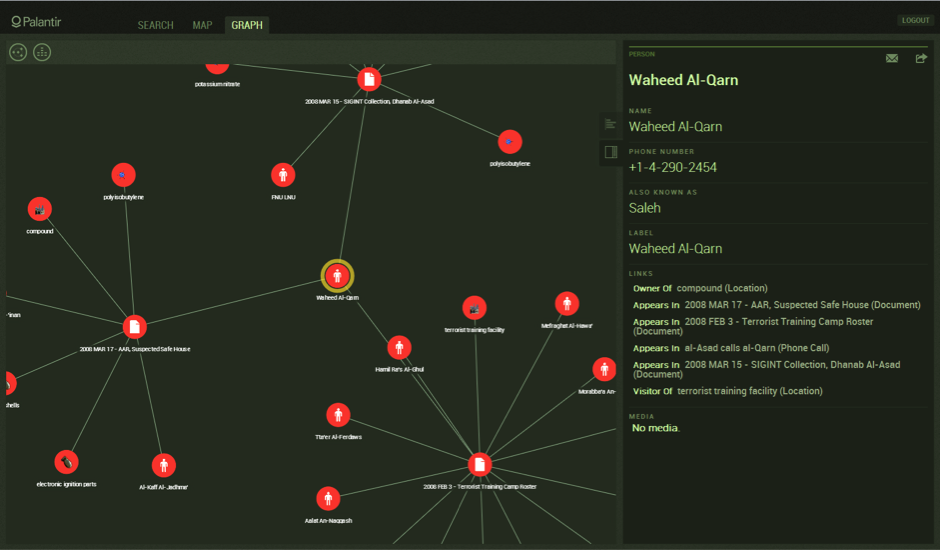
How is life mapped, analyzed and regulated by the algorithmic? To make a beginning of any sort into this complex question, a specific object might be chosen, limiting both the scope of the investigation and the claims which can be made. The object here is Gotham, a software platform developed by the company Palantir. What does Gotham do? Essentially it provides the ability to store, query, and visualize extremely large data sets, allowing analysts to discover patterns and relationships. The concept was born from an insight at the founder’s former company of Paypal. Rather than hard-coded algorithms alone, human and computational agents working together proved better at combating the “adaptive adversary” of financial fraudsters (Palantir, 2016). Gotham provides both automated operations and manual tool sets: algorithms which can be setup to flag anomalies, graphs which visualize the relationships between entities, and the geospatial mapping of resources and agents. These computational tools assist a human analyst in discovering the key signals in a sea of big data noise: a link between terror cells, a transaction from a rogue trader, a location of a stolen vehicle.
Gotham seems emblematic of a shift from the sovereign to software. Granted, Gotham began life as a tool specifically developed for the needs of government institutions: the Department of Defense, the US Army, the NSA, and others. But the promise of big data to provide answers and insights also seemed alluring for other actors holding massive silos of information. The Gotham platform has now been adopted by an array of law enforcement agencies and corporations: BP, Coca Cola, Credit Suisse, NASDAQ, GlaxoSmithKline, the City of New York, the Los Angeles Police Department. In addition, Palantir is not a long-established Washington player, with ‘revolving door’ personnel and matching government contracts. Rather, the company is a decidedly Silicon Valley venture with a matching company culture and long leases in Palo Alto. With a $20 billion dollar valuation, Palantir is the fourth most highly valued tech startup, placing it directly alongside more public companies like Uber and Airbnb (Buhr, 2015). This, then, is not a tale of shadowy intrigue and back-room deals. Rather, I hope to demonstrate how this algorithmic control plays out not in the highly circumscribed spheres of spycraft or the battlefield, but instead spills out into control mechanisms which encompass the everyday practices of ordinary citizens.
Before we begin, a brief word on meaning and method. What is an algorithm? The answers are diffuse. Perhaps this is not surprising for a word which “has recently become a popular, if not dominant, term to refer to when describing the power computational processes have in contemporary forms of life” (Fuller & Harwood, 2015). Speaking broadly, the algorithm is often understood as a recipe for computation or a sequence of operations. Early on in the history of computation, Stephen Kleene defined it as a performable procedure (1943, 59). Barbin et. al have since added properties of finiteness and iteration, “distinguishing it from vaguer notions such as process, method or technique” (2012, 2). However, with its focus on sociality and materiality, this text is interested in a notion expanded beyond the focus on abstraction in mathematics or optimization in computer-science. Indeed, even within these spheres, Gurevich argues that the algorithm cannot be “rigorously defined in full generality” due to a constantly expanding notion of what an algorithm can be and do (2012, 35).
One promising definition of the algorithm was posited by programmer Stephen Kowalski as a combination of ‘logic+control’ (Kowalski, 1979). Logic defines the assumptions and goals of an algorithm, for example, to find a path. Control comprises the routines or techniques used to accomplish it, e.g. the sorting of routes carried out iteratively over time. By separating these two components, Kowalski could focus on optimization, maintaining the overall logic of a programme while finding faster and more accurate means of performing it. The mathematical history of the algorithm focuses on the first component of ‘logic’, allowing for models which are universal and immaterial, abstracted, and idealized. However, the latter term of ‘control’ introduces notions of power, determination, restriction, and management. The term of ‘control’, also suggests techniques and materials—the ability to manipulate something towards an objective. This leads to a crucial question about how these operations are performed: “How does this system become a strategy in action?” (Fuller & Harwood 2015).
Algorithms are often understood as purely abstract procedures. But to perform work in the world, they must mobilize a wider material composition of architectures and organizations, labors and logistics, not to mention “hardware, data, data structures (such as lists, databases, memory, etc.), and the behaviors and actions of bodies” (Terranova 2014, 339). In other words, they are not simple, single objects but flows of heterogeneous materials, forces, and agencies which can be more productively analyzed as algorithmic ecologies [1]. This is an ecology of code and software, certainly, but also surfaces and interfaces, heat and light, bodies and labor, cables and minerals. The ethereal and ideal ‘logic’ is always twinned with ‘control’—the particular performances and strategic configurations of matter necessary to carry it out.
How is the algorithm traditionally unraveled? The traditional notion is a sequential one: first we take this data, secondly we loop through, third we select X from Y, and so on. Of course, this flowchart style approach can be productive for high level understandings and big picture planning sessions. But life does not play out on a whiteboard, with users and matter moving from one discrete state to the next. Indeed, this approach does not even mirror the architectures of present day software production itself, which often takes the form of dozens of microservices. These are services which are highly focused, receiving particular inputs, parsing it through bespoke routines, and outputting a result at maximum efficiency. Microservices aim to bypass the drawbacks of the lumbering mega programme. Instead of a giant and difficult to maintain codebase which performs every operation from start to finish, they’re designed as autonomous and agile components. Rather than the single piece of software waiting for the user to transition from state A to B, complex platforms like Airbnb, Uber and Palantir are better understood as dispersed software services incessantly performing operations.
How might we unpack such complex ecologies of matter? Examining the entire system would appear unproductive if not impossible— a totalization for its own sake resulting in little detail, many repetitions, and much that was irrelevant. Instead, this text takes up the notion of the machine theorized by Levi Bryant. A machine here should be uncoupled from its usual connotations of metal bodies and complex circuitry. Rather, in Bryant’s ontology, all forms of life and non-life can be productively theorized as different types of machines. To speak of the machine is simply to foreground how objects work rather than what they are, to investigate constantly evolving operations instead of some eternally fixed essence. For Bryant (2012), focusing on the machinic highlights questions such as “1) what flows through the thing, 2) how does the thing function or what processes take place in it, and 3) what is produced and how are both the flows and machine changed as a result of these processes?” Machines can be defined by their powers, by what they are capable of. Coupling machines together thus changes not just their appearances, but their abilities—forming new things with new capacities. Bryant explains, for example, that adding the ‘stirrup’ to the ‘horse—rider’ machine was not just a simple addition, but rather fundamentally changed the form of warfare, providing a firm platform which riders could exert pressure against and thereby dramatically increasing the force behind their lances (2011). In Bryant’s ontology, machines might be corporeal (a bridge, a sword, a body), incorporeal (a thought, a poem, a bureaucracy), or typically combinations of the two types.
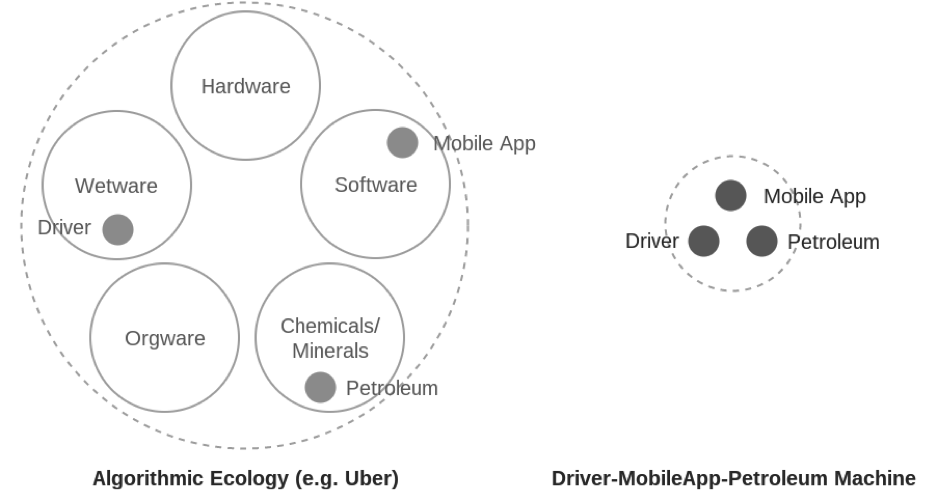
The two machines investigated under the Palantir ecology are sub-selections of the material totality which feel strategic and significant—intersections where software and hardware, labor and nature come together to produce key algorithmic operations. The first machine is composed of several Gotham tools, the ‘stack’ of hardware which powers those tools, and the analyst which uses them to uncover patterns of life. The second machine zeroes in on a particular instance of Gotham, examining how the analyst and license-plate data used by the LAPD comes together in the regulation of life in Los Angeles.
Stack—Tools—Analyst machine
How is a pattern of life established? This section looks at the Stack—Tools—Analyst machine as a subset of the Palantir Gotham ecology. It focuses on the way in which analysis is performed on big data by software or human agents in order to define a particular set of behaviors as the norm. Gotham claims to make sense of life. In order to accomplish this, it must carry out two divergent operations which appear almost contradictory.
On the one hand, Gotham must have life. In other words, the data available and addressable within the platform must approach the richness, variety and speed of the reality ‘out there’. For this objective, messiness, ambiguity and overwhelming amounts of information are not only tolerated, but welcomed as indicators of authenticity. To this end, the layers of backend technologies comprising the Palantir ‘stack’ enable the capture and storage of massive volumes of data which can be queried at high velocity. This is a highly technical performance—a negotiation with scalability and servers, nodes and tables, computation and latency. Simultaneously, however, it is also an ideological performance, supporting the volume, variety and velocity of data required to convince a user or organization that that this data represents reality. I want to look at three requirements to make this vision rational and believable, criteria enacted in turn by three specific backend technologies embedded in the Gotham stack.
Firstly, data must approach petabyte scale. At these magnitudes, big data begins to hold out the promise of a total picture, a set of information which can be incessantly parsed, filtered, sorted, and searched through in order to find the next vulnerability, the latent risk, the dormant operative. This, after all, was the rationale behind the unprecedented amount of data collected by the NSA’s mass surveillance programme, “a wide net that could find and isolate gossamer contacts among suspected terrorists in an ocean of seemingly disconnected data” (quoted in Aradau 2015). That this promise is asymptotic—an incessant programme of capturing ever-more information which never arrives at the horizon of the totality—d0es nothing to diminish its power. How is data made big? One way is through the integration of additional datasets. But disparate databases are often irreconcilable, based on multiple standards, specifications and formats. Another is through the integration of unconventional data. But such information can be incomplete or imperfectly structured. Apache Cassandra, a core component of the Gotham backend ‘stack’, is one way to address some of these issues. The traditional relational database model is comprised of rows and columns, much like Excel. In contrast, Cassandra is a so-called NoSQL approach, a non-relational database with a much more minimal key-value model (e.g. “occupation: doctor, age: 35”). Rather than matching rows and columns perfectly between databases, this nominal ‘schema-less’ structure provides more flexibility when merging datasets. This structure also helps with incomplete data. Rather than wasting man hours and storage by ‘cleaning up’ data (filling in empty cells with zeroes), the NoSQL model means that data can be ‘messier’. In fact, Aradau points out (2015) that big data = messy data has become a new motto of sorts, characterized as “data which comes from multiple sources and in heterogeneous formats.”

Secondly, data must approach the present moment. In an elaborate presentation titled “Leveraging Palantir Gotham as a Command and Control Platform”, a group of engineers demonstrate the capabilities of “Railgun” to an audience of government agencies (Palantir, 2013a). Railgun, they explain, is a layer built on top of the Gotham platform which provides it with “the present tense” (2013a). They visualize and manage the logistics of a (notional) complex humanitarian aid project undertaken by a Marine Corp division as it unfolds. Using real-time tracking data, they follow the progress of naval units off the coast of Somalia, offloading their supplies, transitioning to vehicles, getting stuck at a flood crossing, and ultimately arriving at a Red Cross encampment (2013a). The weekly archive or even the nightly backup comes far too late to assist in making these kinds of decisions. Rather than stable but irrelevant data, then, the engineers assert that they are working with “volatile and ephemeral data” (2013a). The focus is on data as close to the current moment as possible. So while a long-term record might be beneficial, this archive might be populated by “setting a rolling time horizon, beyond which data can be flushed out” (2013a). This constantly fluctuating data initiates a subjective shift from information to animation, from dead symbols to lively avatars. It’s this quality which allows the employees to claim that “more and more, we are sampling reality” (2013a).
Thirdly, data must approach real-time responsiveness. It is not enough simply to have data which can be captured in the present and stored at scale. Data must feel responsive, a quality achieved by ensuring minimal latencies between query and response, even when operating on large datasets. Palantir addresses this by using MapReduce, a core component of the Apache Hadoop system. As the SAS website explains, rather than a single, powerful supercomputer, Hadoop was explicitly designed to distribute processing across hundreds or thousands of consumer grade computers, “commodity hardware.” The basic grouping that Hadoop establishes is the cluster, defined by several key nodes. MapReduce thus serves two essential functions: “It parcels out work to various nodes within the cluster or map, and it organizes and reduces the results from each node into a cohesive answer to a query” (Bigelow and Chu-Carroll, 2015). Mapping in this case allows a basic job, such as word counting a million documents, to be split into batches of one hundred and ‘mapped’ to various nodes. These batches are processed in parallel, leveraging the efficiencies obtained from cloud computation. The figures from these batch jobs are then summed by the Reduce method, which returns the total word count (Apache, 2013). While highly technical and somewhat arcane, it’s this low-level architecture of hardware and software which transforms the experience of interacting with data. Rather than the ‘definitive’ SQL query which might take hours to run on a large dataset, the low latencies afforded by MapReduce create a more conversational experience, in which feedback, iteration and articulation become vital activities, a type of feeling out of the data. Taken together, these three backend technologies accomplish a subjective shift in which it appears that life itself can be exhaustively captured and incessantly interrogated.
So on the one hand, Gotham must expand, extend and encapsulate in order to legitimize its claim of sampling reality. But on the other hand, Gotham must make sense of all of this. By itself, this sheer deluge of data tells us nothing. Information must be worked on, either through automated processes built into the platform or through manual operations: finding threads, constructing sequences, and matching activities in such a way that a pattern emerges. By removing the irrelevant and extraneous, sorting and sifting, the analyst hopes to converge on the weak signal in the midst of overwhelming noise. In this operation too, a kind of tipping point is reached, an accumulation of tiny indicators which slowly edge towards a result. Here too we need to dive into the details, examining how patterns appear to emerge from three specific tools provided by the Palantir Gotham platform.
The first is Search Around, a core feature evidenced by its extensive use in the firm’s online demonstrations. As its name suggests, Search Around can be run on any item, searching for other items which share links and visualizing them as nodes attached in a spiderweb-like fashion (Palantir, 2013c). How are items linked together as similar? In Palantir’s demonstrations using notional data, this took many forms: a flight on the same plane, a shared former residence, a telephone call made to the same third party, a small enough variation in IP addresses (Palantir, 2013b). Two brief points stand out about this logic. Firstly, algorithmic proximity is not geographical proximity—persons separated by great distances are often designated as having close-knit connections and are thus clustered tightly together on the analyst’s screen. As a logic, searching ‘around’ an informational space operates differently than searching around physical space. The logic of data, as Claudia Aradau reminds us, “can draw together even the most distant things” (2015, 24). The power of the visual diagram to perform as evidence should not be overlooked in this regard. Two persons separated by a handful of pixels and connected by a black line might easily eradicate a thousand kilometers. Secondly, these linkages are metonymic not taxonomic—associations are built up by linking small tokens of information from one individual to another, rather than any kind of obvious Linnean clustering. Undoubtedly traditional groupings like race and religion inform analysis, but they no longer maintain their former currency. Instead, as Aradau points out, resemblances in big-data mining are primarily based on “analogy, correspondence and similitude” (2015, 23).
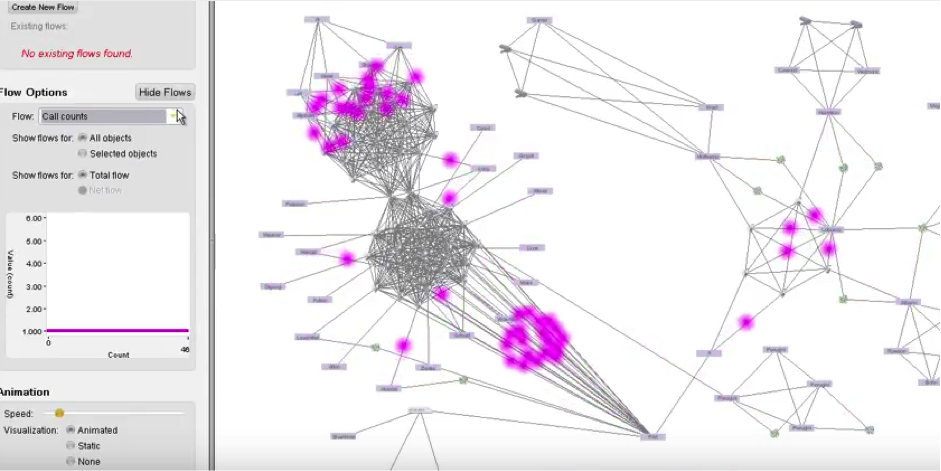
The second tool is Flows, a plugin for Gotham which enables the visualization of material flows. Phone calls, emails, money, or any other material flows understood by the system are visualized as bright dots which move from one object to another over time. This tool produces an array of effects, each tied closely to its formal properties. Flows crystallizes, solidifying connections between entities. Though a line already indicates an association, the bright dot moving from one point to another ‘thickens’ this linkage, visually demonstrating the exchange of matter between one person and another. Flows formalizes, providing a high-level understanding of often very complex networks of objects. The dots of currency or calls often originate from a common ‘hub’ and are received by ‘spokes’, or travel between clusters before jumping to other clusters. This visualization thus provides an impression of structure in the chaotic jumble of network lines—an insight into the arrangement, groupings and hierarchies of actors. Finally Flows prioritizes, providing the analyst with the most important agents in a network. By scaling the size of the dot to the magnitude of matter (number of phone calls, amount of money, etc), significant transactions and interactions stand out easily in the visualization and can be flagged for further investigation.
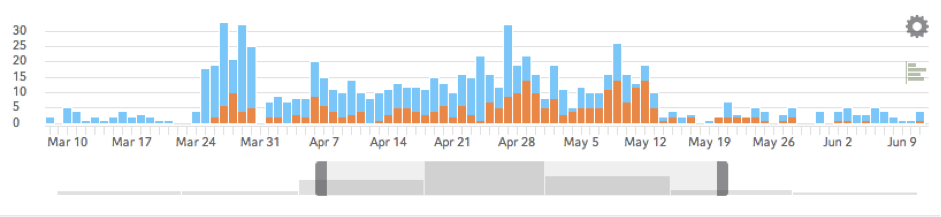
The third tool is the Timeline. This takes the form of date and time indicators in a module along the bottom of the screen. The tool allows the analyst to specify a ‘time window’ of a few seconds, hours or days. This isolates the action, only visualizing the events or activity which occurred during that period. This window can be dragged incrementally along the Timeline, providing the analyst with a ‘play by play’ of events as they unfolded. The key intent here, like the other tools, is to uncover a discernable pattern, a particular signature of activity. The human analyst stands in for the algorithmic, operating according to the same logic of analogy, correspondence and similitude. Do events seem coordinated, occurring at roughly the same times? Is there a particular sequence of behaviour which is constantly repeated? Do the seemingly random activities of a network become cyclical or consequential over time? Conversely, is there a rupture or break in these habitual routines which appears significant? To answer these questions, Timeline is often coupled with Flows to uncover a pattern of action. In one of Palantir’s ‘notional’ demonstrations, the analyst discovered that three operatives were receiving phone calls, then two days later were transferring finances to a particular account, a sequence which repeated weekly. One month later, these operatives all boarded a plane on the same day, bound for the same city of Chicago (Palantir, 2011). While the ‘insights’ discovered during these demonstrations are inherently staged, they provide a compelling vision which is taken up by a range of public and private actors; a powerful fantasy in which a pattern emerges from the data deluge, uncovering an imminent terror threat or financial risk, revealing the next management optimization or consumer trend.
Analyst—Thunderbird—Los Angeles machine
How is life regulated? Following on from the pattern of life, this section examines the Analyst—Thunderbird—Los Angeles machine to investigate this question. Thunderbird is Palantir’s name for the automated license plate reader system integrated into the version of Gotham platform used by the Los Angeles Police Department (LAPD). While the analyst’s use of license plate data provides the impetus for intervention, this regulation is carried out by a complex juridico-political network of human and non-human elements: inspectors and lawyers, sensors and governors, license-plate readers and police. This machine is performed incessantly, distributed ubiquitously, and maintained silently. Its presence, in turn, necessitates the need for subjects to self-regulate, managing their own life processes in a self-initiated performance.
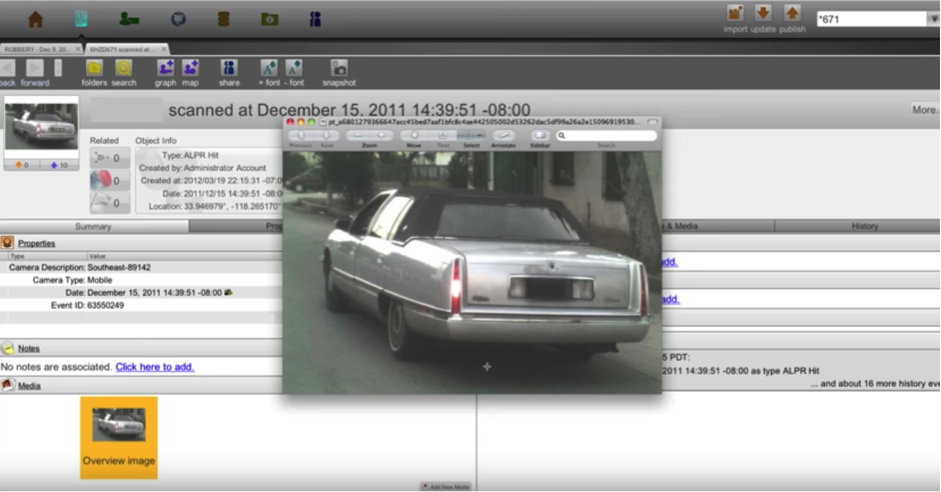
The Los Angeles police department was one of the first law enforcement agencies to adopt the Palantir platform. Indeed, a 2013 video produced by the company uses the LAPD as an exemplary case study, a series of complimentary testimonials in which the chief credits the platform with helping them “make sense of all the noise that’s out there” (2013d). In 2014, the department doubled down, spending another $2.9 million for a contract for Palantir “to furnish, configure, and install a new upgraded module to LAPD’s existing platform and to incorporate new data” (Office of the City, 2014). The contract details the addition of new data modules comprising license plate data which is routinely collected, mug shots from the local county as well as an array of information available from the Department of Motor Vehicles: home address, home telephone number, physical/mental information, social security number, and a photograph (2016).
This expansion of accessible data and the integration of it into the unified Palantir platform seeks to create a more comprehensive informational environment. In this way, Thunderbird exemplifies the two contrasting operations sketched out in the previous section—voraciously expanding the scope of data capture while simultaneously providing tools and functionality to converge towards a particular target. As Ian Shaw explains, “The entire ‘normal’ population must first be coded and modeled to geolocate the abnormal. In order to individualize, the security state must first totalize, effecting an intensive policing of the lifeworld. The two spatial optics of urban manhunting are thus population (expansion) and person (contraction)” (2016, 25). A key goal here is the need to ‘capture it all’, the quest towards the totalization of information which is supported on a technical level by the Palantir stack. To be able to locate any individual, it is first necessary to know every individual, entailing the representation of a mass population through data.
How does this information come together in the regulation of life? License plate data is automatically captured by dedicated reader equipment manufactured by a third party, most commonly Vigilant Technologies. A fixed license plate reader is commonly attached to a light pole, capturing plates of cars passing beneath it and transmitting them directly back to law enforcement headquarters. A mobile version, used heavily by the LAPD, takes the form of two cameras mounted on top of the police cruiser. The mobile readers operate continuously, detecting plate imagery from within their visual feed, isolating and converting it to a sequence of alphanumeric characters, and adding this to a scrolling list of plate data on a monitor inside the car. These plates are checked against state and federal databases to match against particular activity. The Federal Bureau of Investigation, for example, maintains a special machine-readable file for plate reader systems which is refreshed twice daily. The vehicle might have been reported stolen, it might be registered to a sex offender who is violating his parole, or it might belong to a so-called scofflaw who has routinely ignored parking fines. Once flagged, the corresponding series of operations plays out on the owner of the vehicle—an arrest, a fine, a warning, and so on. In this way, every plate hides a potential crime. In fact, as Al-Jazeera reported (2016), the LAPD recently denied a Freedom of Information Act request based on the grounds that the plate data is investigatory. In other words, all cars in Los Angeles are under ongoing investigation.
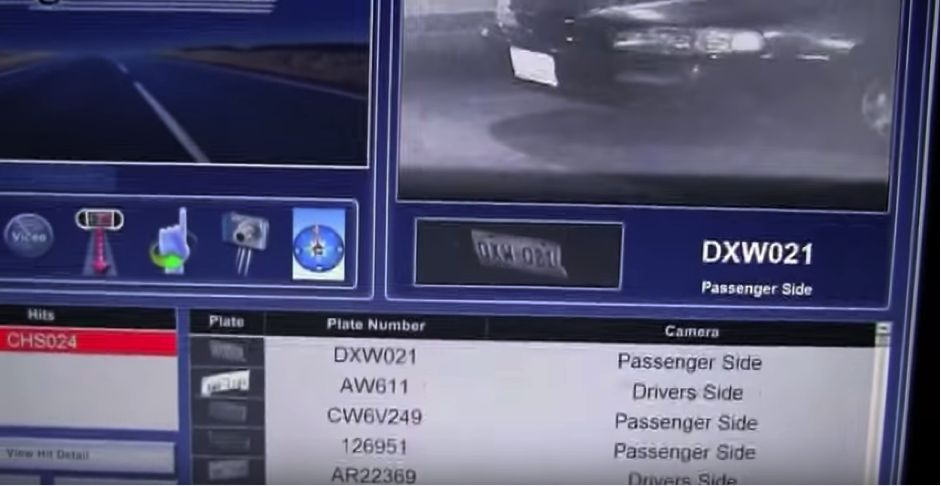
Critics of technology and surveillance often conjure up the nightmare scenario in order to build public support for their stance: the global glitch, the rogue employee, the fatal error. Of course, these unforeseen situations can occur and do matter. Their consequences often fall heaviest on those groups already marginalized or vulnerable. For example, Denise Green, an African-American woman, was pulled over in 2009 when automatic license plate reader technology mistook a ‘3’ for a 7’, flagging her car as stolen (Winston 2014). Officers ordered her out of the vehicle at gunpoint, forced her to her knees and handcuffed her while they searched her car. Green, a 50-year-old bus driver, described the experience as a “nightmare” and had to take 2 weeks off for counseling (Winston 2014).
But these cases are anomalies. A more subtle and systemic effect occurs in those proximate to the subject and in the wider population as a whole. As Brendan O’Connor (2016) reminds us, “a nightmare scenario of an Office of Special Enforcement inspector going rogue, stalking a colleague or creditor or lover with Palantir’s mobile technology, is certainly conceivable. But the potential for that kind of outright abuse is less disturbing than the ways in which Palantir’s tech is already being used. The city’s embrace of Palantir, outside of law enforcement, has quietly ushered in an era of civil surveillance so ubiquitous as to be invisible.” This silent regime runs as a low-level hum in the background, an undercurrent informing (and more precisely, discouraging) a range of political practices.
‘A chilling effect’ is the term used to describe this subtle cooling, a subliminal process in which the subject self-regulates activities which might be deemed political or controversial. In 2009, the Association of Police Chiefs commissioned a report investigating the potential ethical implications caused by the automated capture of license plate data on a mass scale. Though unsurprisingly glowing in its overall outlook, the authors did caution organizations about this potential chilling, warning that populations exposed to the technology might become “more cautious in the exercise of their protected rights of expression, protest, association, and political participation” (Tracy, Cotter and Nagel, 7).
But is this chilling effect merely anecdotal or imaginary, an outcome simply assumed by those concerned with surveillance and privacy? In 2016 Jon Penney conducted one of the first empirical inquiries into these effects. Penney focused on the Snowden/NSA revelations of June 2013, honing in on that moment when the world learned that the US government was conducting mass surveillance of their phone calls, web searches, and other everyday activities increasingly conducted online. Contrary to many surveillance operations which remain undisclosed, the Snowden revelations were a highly publicized bombshell which alerted a broad public that their activities were actively being monitored. Penney analyzed the traffic of 48 ‘controversial’ Wikipedia articles—pages like ‘dirty bomb’ and ‘suicide attack’ related to terrorism and other topics likely to raise surveillance flags (2016, 140). Penney discovered that after the revelations in June 2013, visitors to these pages dropped by 20%. What’s more, this was not a temporary drop-off, but part of a longer lasting effect. Penney notes, for example, that viewership of the wiki article on ‘Hamas’ was previously trending up, gaining 60,000 views per month. Post Snowden, however, this trend reversed, with 20,000 fewer people visiting the page month after month (2016, 151). The study demonstrates that, contrary to the mantra of ‘nothing to hide, nothing to fear’, subjects under surveillance do regulate their own behavior, albeit unconsciously. [2]
Of course, Palantir is not the NSA and Gotham is not the PRISM programme. We must be careful too not to overburden this object, ascribing a whole range of overwhelming and nebulous effects to its operations. Indeed, one of the key subjectivities of Palantir’s processes is just how incredibly banal they become. The functionality can be learned in a day of workshops (Woodman, 2016). The interface is designed to be highly intuitive. Point and Click. Drag and Drop. There’s nothing particularly awe-inspiring here, no technology which points to its own spectacle. Rather, the whole activity becomes depoliticized precisely to the extent to which it is deemed ordinary and procedural. At the same time, we must acknowledge those capacities, sketched out in the previous section, which Gotham provides: the assimilation of unstructured data, the conversational query and retrieval of information, the cross-referencing of properties and a progressive accumulation of associations leading to the formation of an ostensibly organic pattern. Integrating license-plate data into this platform via Thunderbird adds new capabilities: the tracking of behaviors over time and the ability to locate a subject in space. This is a radical amplification of surveillance capabilities—facilitating the targeting and interrogation of subjects on massive scales. Gotham thus provides both a significant expansion in the scope of data analysis while simultaneously facilitating an effortlessness in their use—an economization of regulation.
For Foucault, this progression from the costly to the economic has always been the trajectory which power takes, a trajectory which Jeffrey Nealon (2008) draws out through the notion of intensification. For Nealon, this thread provides power with both a goal and guidance—constituting an overall objective and defining the transformations necessary to achieve it. In order to be effective, power must be flexible rather than fossilized, evolving over time in particular ways. As Nealon explains (32), this constant reconfiguration precedes not randomly but logically, playing out in “the formulaic movement of power’s intensification: abstraction, lightening, extension, mobility, and increased efficiency.” Discipline and Punish highlighted a section of this trend, an evolution from the violent punishments enacted directly on the body and the brick-and-mortar incarceration of the flesh towards a much lighter and efficient regime, embodied for Foucault at that time in Bentham’s designs for the panoptic prison. New embodiments within this trajectory move incrementally towards a more effective performance which can be attained more ‘economically’ in every sense: materially, financially, temporally, and so on.
One of the key logics here is a shift from the somatic to the systemic. Disciplinary power is often understood as a more traditional form of control exerted on the body through prisons, barracks, hospitals, and so on. But the panoptic prison anticipated, even if weakly, the trajectory of power away from physical presence. As Foucault noted (1995, 255), “power has its principle not so much in a person as in a certain concerted distribution of bodies, surfaces, lights, gazes; in an arrangement whose internal mechanisms produce the relation in which individuals are caught up.” Somatic power relying on bodily intervention is both expensive to maintain and constrained inherently by the corporeal—a particular body with a limited line of sight, a finite span of attention, a fixed number of work hours, and so on. This is why Nealon (2008, 34) suggests that intensity strives incessantly towards a more efficient “smearing or saturation of effects over a wide field,” a form of control which can be suffused into and across a particular space. The warden can be replaced with the guard, the guard with the dummy. In the end, the watch tower can be emptied entirely. The arrangement of cells at particular angles, the centrality of the tower and the masked windows all constitute a system which amplifies the disciplinary potential of vision. This system acts to distribute the effects of power equally throughout the space—the gaze is decoupled from the warden and embedded into the walls themselves, becoming ubiquitous and ever-present.
To update this disciplinary gaze, we might posit something like an algorithmic gaze—a gaze which operates not on the body directly, but on its data shadow—indexing the swirl of information produced by the subject and associated with him: credit scores and criminal records, phone calls and chat logs, Skype calls and social media. In doing so, informational technologies maintain a diffused and largely imperceptible field—-a steady pressure which obliges the subject to adopt particular practices of self-regulation. Gotham, for its part, acts as both interface and integrator for these systems—a glue to bind together disparate data and a GUI to inspect it. While the ability of physical visibility to produce self-governing inmates might have been overstated in Foucault’s time, the tendency of the subject towards self-governance in the hard light of algorithmic visibility seems decidedly less so. Regulation shifts from external coercion to internal conformity, an incessant performance which is both self-initiated and self-managed. As Foucault (1995, 256) reminded us, once these forces are instantiated, “he makes them play spontaneously upon himself; he inscribes in himself the power relation in which he simultaneously plays both roles; he becomes the principle of his own subjection.”
Despite these tendencies, power is never totalizing. There are always errors and inconsistencies present in the algorithmic. But the particular modalities of this power indicate that traditional framings and responses may prove relatively ineffective. Take, for example, the notion of ‘resistance’. Algorithmic power is not a corporeal body which oppresses and can thus be pressed against. Rather, as our Foucauldian reading suggested, this power is highly diffuse, infused into the mechanisms of informational systems. In this sense, Gotham is more akin to a saturated field laid over a topography of subjects. Humanity and technology are bound up intimately within this environment, interdependent and inextricable. As Verbeek (2013, 77) asserts, “conceptualizing this relation in terms of struggle and oppression is like seeking resistance against gravity, or language.” This is not to collapse into fatalism, but simply to recognize that the traditional language of ‘oppression’ and ‘resistance’ needs to be updated or even supplanted.
A second notion which may require updating is that of ‘refusal’, consciously opting out of particular platforms or informational systems. The extent to which this is even possible in any holistic way for those in the Global North is debatable, though some partial non-participation is indeed feasible. Of course, refusal itself is often only feasible for those who already possess a certain degree of privilege: an established reputation, offline social support structures, a stable career, and so on. This leads to one of the core reasons why refusal may be ineffective—it often seems to disenfranchise more than it empowers, excluding the subject from life-enhancing realms of cultural, social, and financial exchange. In Seb Franklin’s (2015, 136) words, “disconnection from channels of communication appear aberrant or pathological and thus lead to expulsion from circuits of representation and inclusion.” The subject becomes cut off from vital networks, a move which costs them greatly while effecting the system very little.
In contrast, the Analyst—Thunderbird—Los Angeles machine suggests some immanent but unexpected strategies, informational flows which are shifted laterally by some material friction and subsequently come out somewhere different, producing an inconsistency or inefficacy. Several tangible examples are mentioned in a 2014 Rand report by Gierlack et al. For instance, the report notes that the LPR camera systems are configured to function in both day and night settings, necessitating the capture of both infrared and visible photos of the car plate in high definition. The volume of this ‘doubled’ data is entirely unexpected, often overwhelming the storage systems of law enforcement agencies, forcing organizations to erase old data to free up space for new data. The result is that “these limits, rather than privacy concerns, ended up shortening their data retention period” (2014, 68). Rather than any overt intervention from outside—government regulation or citizen activism, for example—the processes within the system itself work to undermine its own efficacy. In another example, the complexity of the natural and built environment creates unexpected frictions which the algorithmic fails to resolve. As the report elaborates, “The cameras also can false-read structures as license plates, as one department found when its system kept seeing wrought-iron fences around some homes as “111-1111” plates” (2014, 80). This glitch is generated by the disparity between the messiness of the outer world and the expected informational inputs of the code world.
Putting these two inconsistencies together, we arrive at a final example. The report discloses that “drivers have beaten the system by using black electrical tape to alter their license plates” (2014, 100). Automated license-plate reader systems all contain particular assumptions about the visual schema to be expected—darker pixels situated on the white background of the plate itself which should resolve into a sequence of alphanumeric characters. By injecting unexpected matter into the ecology—tape stuck between plate characters—the expected algorithmic flow runs but is diverted or interrupted. The resulting output is deemed valid by the machine but useless to humans. This practice doesn’t ‘resist’ the system (shut down the servers?), nor ‘refuse’ it (stop driving altogether?). Rather, this practice works with the system rather than against it, understanding the operational logics at work, playing with these processes and exposing them to unexpected inputs. This feels like a more strategic practice—one which recognizes how entangled we are with technological systems while at the same time instrumentalizing particular inconsistencies within these systems in order to counterbalance their often asymmetric power structures.
Conclusion
Palantir Gotham provides a way into exploring some of the complex ways in which algorithmic operations structure subjectivities today. The algorithm is not just composed of an abstracted and immaterial ‘logic’ component, but also the ‘control’ mechanisms which carry out its work in the world—an ecology of sensors and software, bodies and bureaucracy, hardware and minerals. By investigating strategic intersections of matter as ‘machines’, specificities inherent in the algorithmic are revealed, particular ways of understanding and acting on the world. The Tools—Stack—Analyst machine shows several of the methods by which the algorithmic parses information in order to establish patterns of life. The backend ‘stack’ enables these tools with operations which support massive volumes of real-time data which can be queried responsively, operations which come together to make data analogous to life. The Analyst—Thunderbird—LosAngeles machine uses a particular Gotham instance to sketch out the algorithmic regulation of life. The automated license plate reader data of Thunderbird initiates an informational field used to make correlations, track activities and locate subjects in space. The resulting regulation often plays out as modulations of life forces, inhibiting abilities indirectly through citations, evictions, fines and so on. This power is systematic rather than somatic, an arrangement of internal mechanisms which acts in light and economic ways. This regulation, in turn, exerts a pressure towards self-regulation, a self-initiated programme of governance performed incessantly. But the algorithmic is inconsistent—these errors point the way towards more effective means of intervening within contemporary modes of control.
Notes:
[1] This term is preferred over the very general “assemblage” (DeLanda) or even the more targeted “media ecologies” (Fuller) in that it foregrounds the logical, procedural forces of informational systems (algorithmic) which must enlist a variety of bodies and surfaces in order to carry out work in the world (ecologies)
[2] The full methodology and details of Penney’s study is outside the scope of this text. The study, however, does provide some nominal empirical support to an assumption which has been difficult to measure, namely that surveillance like that carried out by Palantir’s clients has effects which diffuse into wider populations in subtle and subliminal ways, moving far beyond those impacted ‘directly’ through violence, incarceration, deportation, and so on.
References:
Al Jazeera America. 2016. “LAPD: All Cars Are Under Investigation.” Al Jazeera. Last modified March 25. http://america.aljazeera.com/watch/shows/the-stream/the-stream-officialblog/2014/3/25/lapd-all-cars-areunderinvestigation.html.
Apache. 2013. “MapReduce Tutorial.” Hadoop 1.2.1 Documentation. Last modified April 8. https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html.
Aradau, Claudia. 2015. “The Signature of Security: Big data, anticipation, surveillance.” Radical Philosophy 191: 21-28. https://www.radicalphilosophy.com.
Barbin, Evelyne, Jacques Borowczyk, J-L. Chabert, Michel Guillemot, Anne Michel-Pajus, Ahmed Djebbar, and J-C. Martzloff. 2012. A History of Algorithms: from the Pebble to the Microchip. Edited by Jean-Luc Chabert. Springer Science & Business Media.
Bigelow, Stephen, and Mark Chu-Carroll. 2015. “What is MapReduce?” SearchCloudComputing. http://searchcloudcomputing.techtarget.com/definition/MapReduce.
Bryant, Levi. 2011. “Two Types of Assemblages.” Larval Subjects. Last modified February 20. https://larvalsubjects.wordpress.com/2011/02/20/two-types-of-assemblages/.
Bryant, Levi. 2012. “Machinic Art: The Matter of Contradiction,” Larval Subjects. Last modified July 24. https://larvalsubjects.wordpress.com/2012/07/22/machinic-art-the-matter-of-contradiction/.
Buhr, Sarah. 2015. “Palantir Has Raised $880 Million At A $20 Billion Valuation.” TechCrunch. Last modified December 23. https://techcrunch.com/2015/12/23/palantir-has-raised-880-million-at-a-20-billion-valuation/.
Department of Motor Vehicles. 2016. “DMV and Your Information.” State of California. Accessed November 19. https://www.dmv.ca.gov/portal/dmv/detail/dl/authority#info.
Federal Bureau of Investigation. 2011. License Plate Reader Technology Enhances the Identification, Recovery of Stolen Vehicles. Washington, DC: United States Department of Justice.
Foucault, Michel. 1995. Discipline and punish: the birth of the prison. New York: Vintage Books.
Francescani, Chris. 2014. “License to Spy.” Backchannel. Last modified December 2. https://backchannel.com/the-drive-to-spy-80c4f85b4335#.wc45mo7uo.
Franklin, Seb. 2015. Control: Digitality As Cultural Logic. Cambridge, MA: MIT Press.
Fuller, Matthew, and Graham Harwood. 2015. “Algorithms Are Not Angels.” Future Non Stop. http://future-nonstop.org/c/bed167c89cc89903b1549675013b4446.
Gierlack, Keith, Shara Williams, Tom LaTourrette, James Anderson, and Lauren A. Mayer. 2014. License Plate Readers for Law Enforcement: Opportunities and Obstacles. Santa Monica: RAND Corporation.
Gurevich, Yuri. 2012. “What Is an Algorithm?” SOFSEM 2012: Theory and Practice of Computer Science: 31-42. doi:10.1007/978-3-642-27660-6_3.
Kowalski, Robert. 1979. “Algorithm= logic+ control.” Communications of the ACM22, no. 7: 424-436.
The Mayor’s Office of Homeland Security and Public Safety. 2015. Fiscal Year 2014 Urban Areas Security Initiative Grant. Los Angeles: Office of the City. http://clkrep.lacity.org/onlinedocs/2014/14-0820_misc_5-18-15.pdf.
Nealon, Jeffrey T. 2008. Foucault Beyond Foucault: Power and Its Intensifications Since 1984. Stanford, Calif: Stanford University Press.
O’Connor, Brendan. 2016. “How Palantir Is Taking Over New York City.” Gizmodo. Last modified September 22. http://gizmodo.com/how-palantir-is-taking-over-new-york-city-1786738085.
Palantir. 2016. “About.” Palantir. Accessed December 22. https://www.palantir.com/about/.
Palantir. 2012. “Dynamic Ontology.” YouTube. Last modified July 5. https://www.youtube.com/watch?v=ts0JV4B36Xw.
Palantir. 2011. “GovCon7: Introduction to Palantir.” YouTube. Last modified November 2. https://www.youtube.com/watch?v=f86VKjFSMJE.
Palantir. 2013. “Palantir at the Los Angeles Police Department.” YouTube. Las modified January 25. https://www.youtube.com/watch?v=aJ-u7yDwC6g.
Palantir. 2013. “Prepare, Detect, Respond, And Harden: Palantir Cyber In Action.” YouTube. Last modified June 4. https://www.youtube.com/watch?v=6mIQmL2Lapw.
Palantir. 2013. “Railgun: Leveraging Palantir Gotham As a Command and Control Platform.” YouTube. Last modified February 8. https://www.youtube.com/watch?v=ZSB0wOMINhg.
Palantir. 2013. “Search Around.” YouTube. Last modified September 12. https://www.youtube.com/watch?v=–iIaUvn4kc.
Penney, Jonathon. 2016. “Chilling Effects and the DMCA: An Empirical Case Study.” SSRN Electronic Journal 31, no. 1: 117. doi:10.2139/ssrn.2757778.
Shaw, Ian G. 2016. “The Urbanization of drone warfare: policing surplus populations in the dronepolis.” Geographica Helvetica 71, no. 1: 19-28. doi:10.5194/gh-71-19-2016.
Studer, Rudi, Richard Benjamins, and Dieter Fensel. 1998. “Knowledge engineering: Principles and methods.” Data & Knowledge Engineering 25, no. 1-2: 161-197. doi:10.1016/s0169-023x(97)00056-6.
Tracy, Meghann, Heather Cotter, and William Nagel. 2009. Privacy impact assessment report for the utilization of license plate readers. Alexandria, Virginia: International Association of Chiefs of Police. http://www.theiacp.org/Portals/0/pdfs/LPR_Privacy_Impact_Assessment.pdf.
Verbeek, Peter-Paul. 2013. “Resistance Is Futile.” Techné: Research in Philosophy and Technology 17 no. 1: 72-92. doi:10.5840/techne20131715.
Winston, Ali. 2014. “Privacy, Accuracy Concerns As License-plate Readers Expand.” SFGate. Last modified June 17, 2014. http://www.sfgate.com/crime/article/Privacy-accuracy-concerns-as-license-plate-5557429.php.
Woodman, Spencer. 2016. “Documents Suggest Palantir Could Help Power Trump’s ‘Extreme Vetting’ of Immigrants.” The Verge. Last modified December 21, 2016. http://www.theverge.com/2016/12/21/14012534/palantir-peter-thiel-trump-immigrant-extreme-vetting.